
用Python爬取5000张手机高清壁纸大图
数据源分析
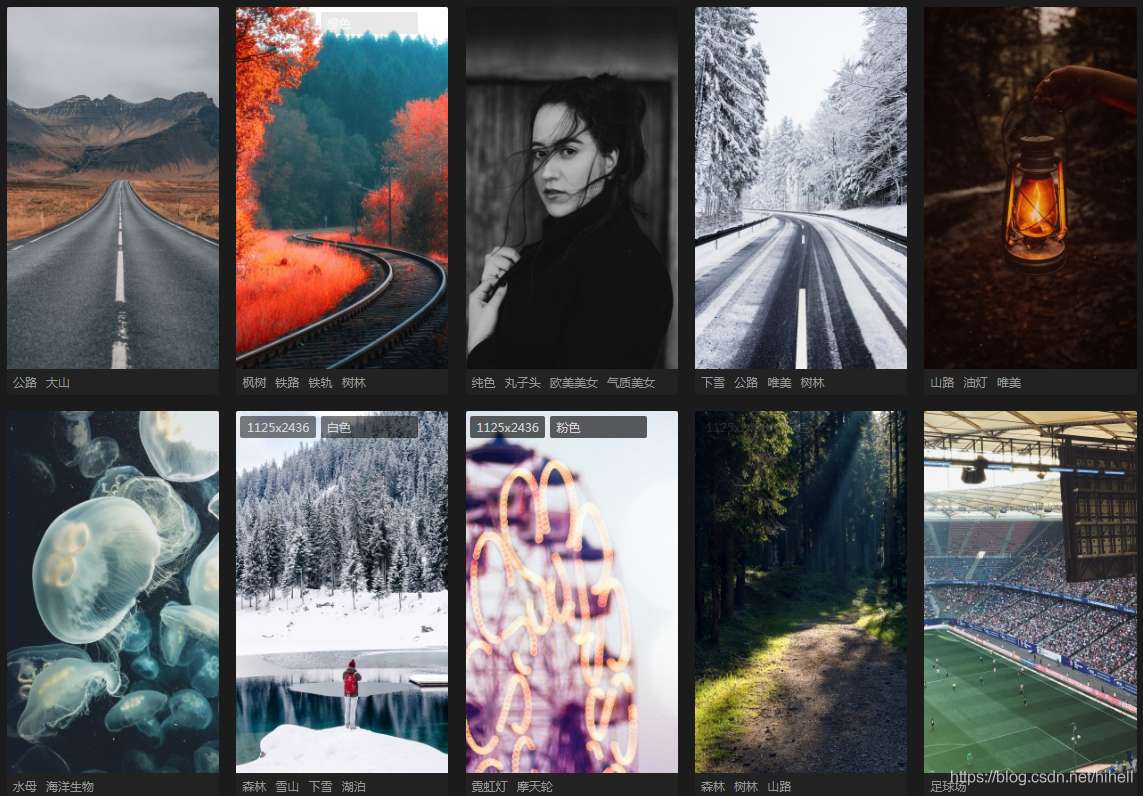
爬取目标
使用的 Python 模块
本次使用 requests,re,threading。
threading 模块将在本案例中,进行分页多线程抓取。
列表页分析
分析列表的时候发现,该网站可以直接通过,修改列表页图片地址获取高清地址,有这样的技巧存在,就能大幅度减少爬虫代码编写量,具体如下。
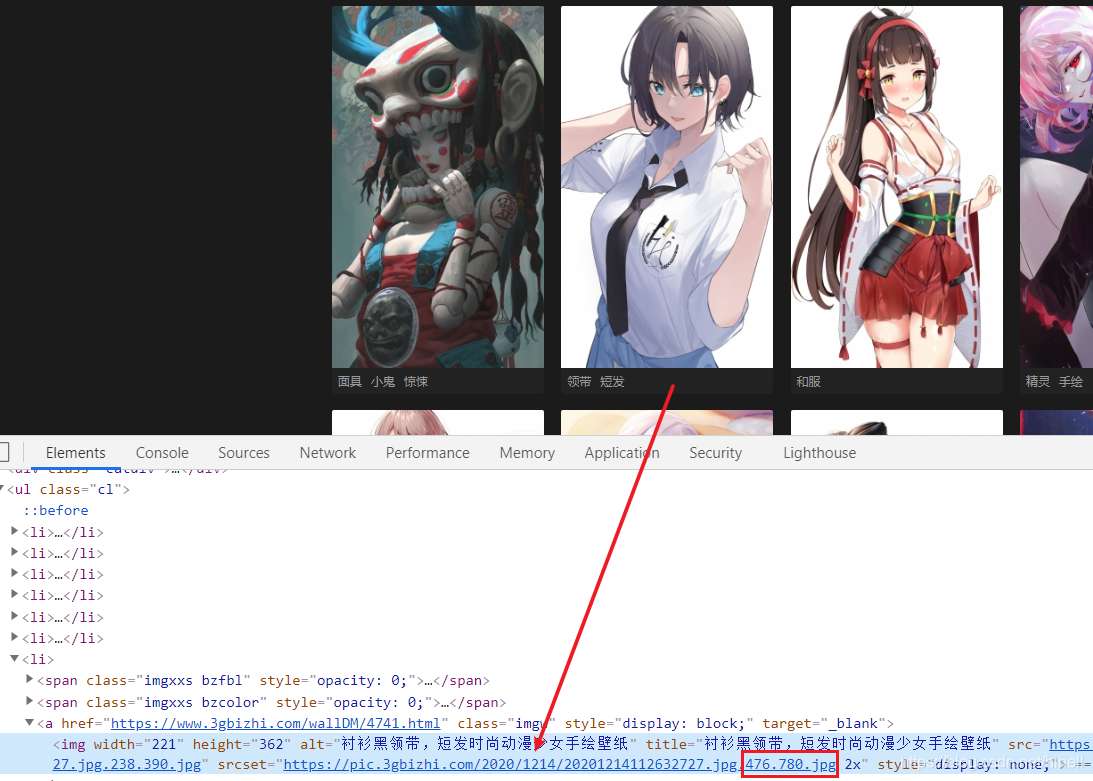
通过浏览器检查图片标签,获得如下图所示图片地址,即 https://pic.3gbizhi.com/2020/1214/20201214112632727.jpg.476.780.jpg
在浏览器中打开该地址,得到一张图片预览地址,去除 .476.780 相关内容,直接获取到大图地址,即 https://pic.3gbizhi.com/2020/1214/20201214112632727.jpg
既然可以通过列表页直接获取大图地址,那针对该网站的爬取,直接通过列表页即可实现。下面就可以针对分析进行需求的整理工作。
整理需求如下
爬取目标网站列表页;
分析图片大图链接;
请求图片,保存图片。
编码时间
在上文针对列表页面进行了数据上的分析,接下来就可以对其进行代码编写了。
此时获取到的就是图片的真实地址,调用 save_image 函数,对远程图片进行存储。其中 title 为图片存储地址。
最后使用多线程进行爬取,开启 5 个线程,当所有线程结束运行时,停止整体代码。
运行我们的爬虫程序,会看到图片批量的存储到了本地。
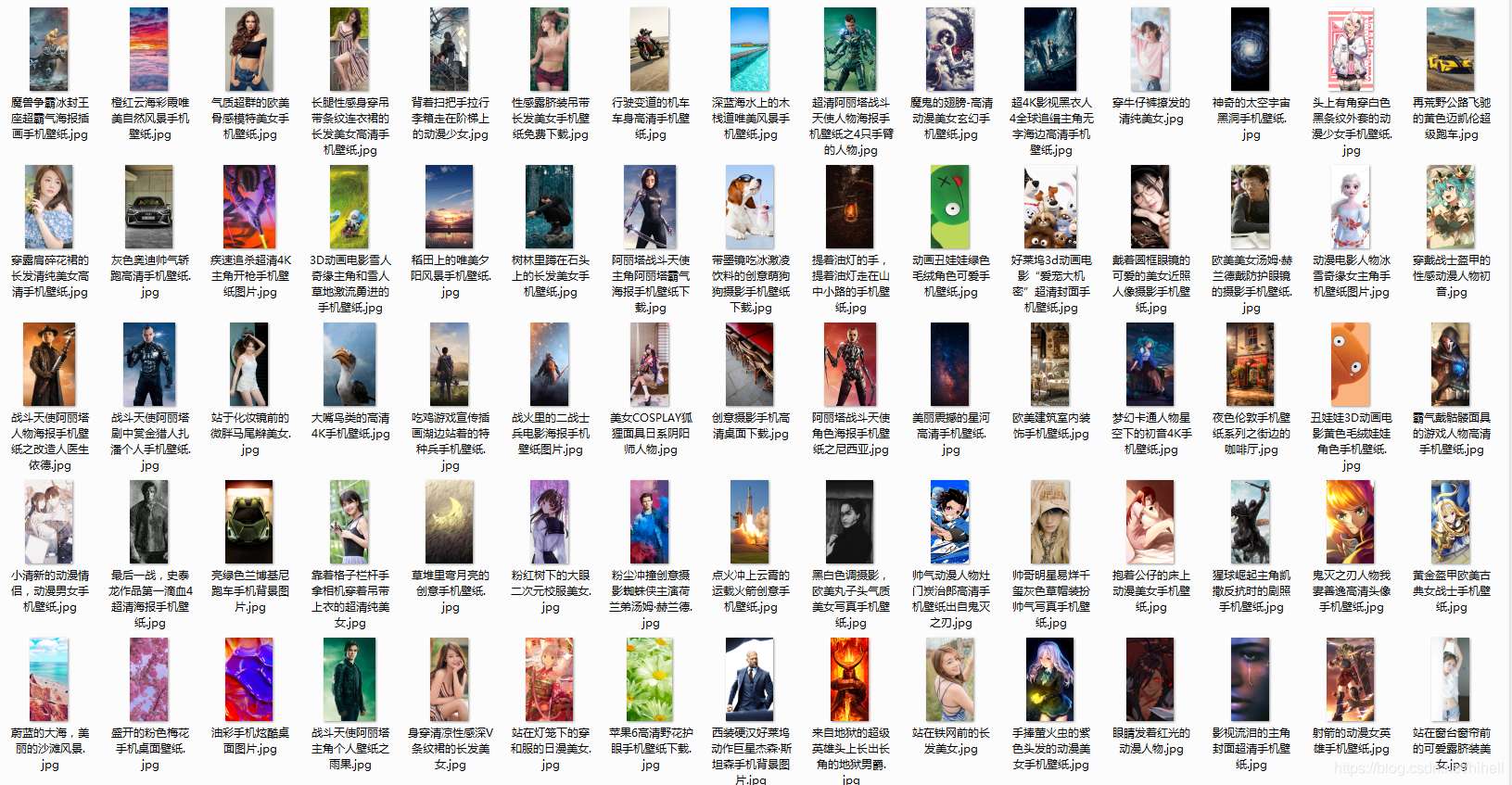
抓取结果展示时间
抓取到非常多优质的手机壁纸,换到手机不能用,都用不完了。
完整代码下载地址:https://github.com/PeterCoast/Python_code/tree/master/NO1
代码编写过程中,顺手爬取了一堆图片,可以提前预览一波,看看图,在决定是否运行这段代码。
3k张壁纸:https://ws28.cn/f/60sdbzsqqp1 密码:1188
© 版权声明
本站收集的资源仅供内部学习研究软件设计思想和原理使用,学习研究后请自觉删除,请勿传播,因未及时删除所造成的任何后果责任自负。
如果用于其他用途,请购买正版支持作者,谢谢!若您认为「KKOK.CC」发布的内容若侵犯到您的权益,请联系站长邮箱:ezuw@qq.com 进行删除处理。
本站资源大多存储在云盘,如发现链接失效,请联系我们,我们会第一时间更新。相关文章



暂无评论...

❯




